AI agents and the web - A proposal to keep developers in the loop
In this post, I'll introduce WebMCP, a proposal to let you, web developers, control how AI agents interact with your web pages. If this proposal is interesting to you, please let me know. I'm looking for early feedback!
AI agents and the web
AI agents are sort of taking over the way we use computers. The way we do things on computers, whether it's doing tasks, or searching for information in documents or on the web, is changing. The promise here is that you should be able to just say what you want to do in plain language, and let an AI agent take it from there. I'm personally not there yet, but things certainly seem to be headed in that direction.
Part of this promise requires that AI agents be able to navigate to web pages, read content, and sometimes perform actions on them. It's not enough for the agent to respond to a question based on its own training data, it now also needs to interact with live content and do things on the user's behalf. And some of these things might need to happen on web pages.
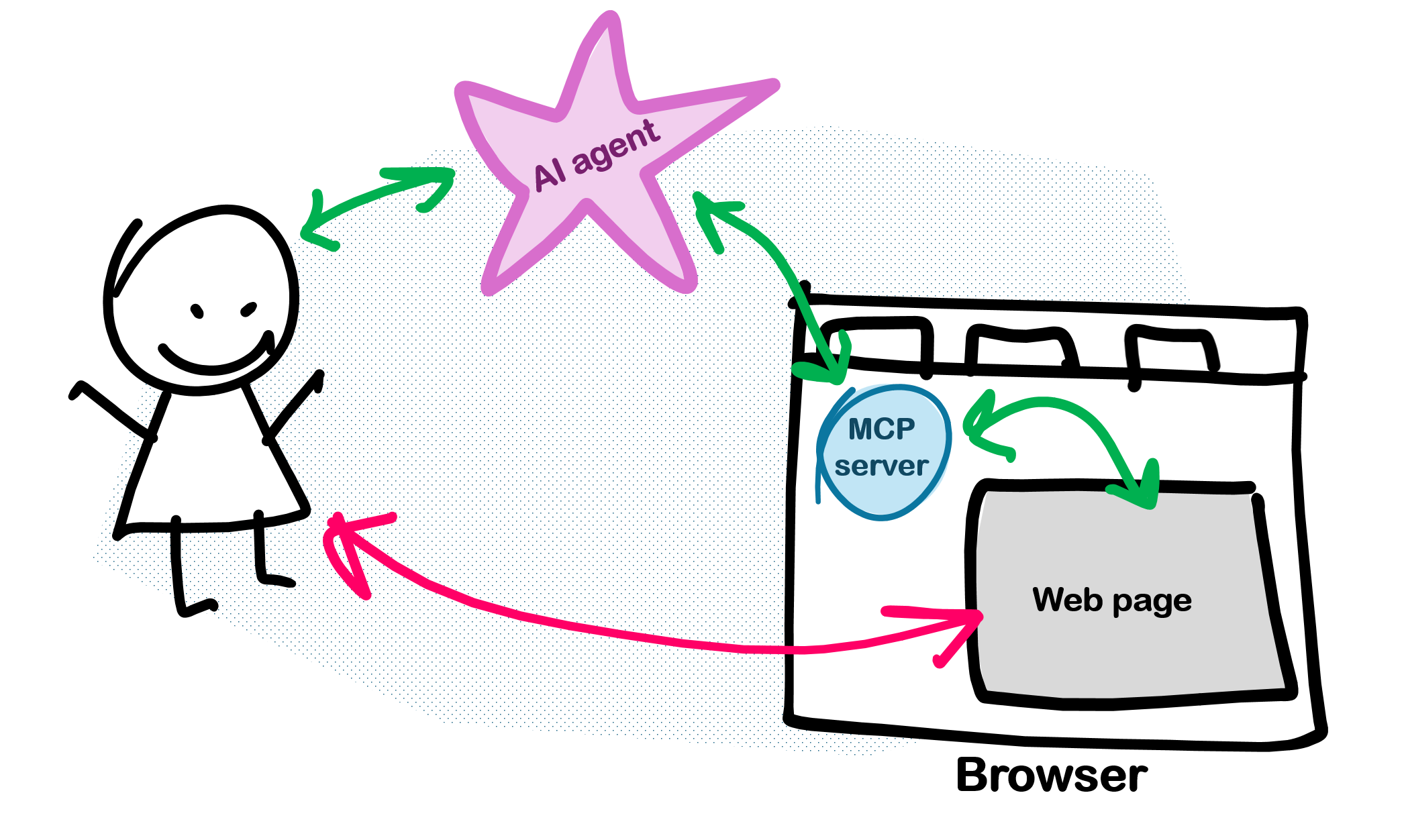
Sometimes, that means the AI agent accesses the website's backend, via some kind of remote service. But other times, the AI agent needs to actually use the browser like a user would, navigating and scrolling around, getting content, and performing actions. This might be by extracting text and meaning from the DOM tree, or the accessibility tree, or by processing screenshots.
When it comes to agents performing actions on the web though, such as filling and submitting forms, things tend to get a little more complicated. Would the AI agent find the right fields and buttons by looking at the DOM? What if the developer used <div>s instead of <button>s? Would the AI agent better understand what to do by looking at screenshots instead? Not sure.
More importantly, should you, the developer of the page, have a say in how the AI agent is using that page?
The Edge and Google teams believe so, and have been working together on a proposal called WebMCP.
WebMCP
At its heart, WebMCP lets you list the actions (called "tools") that an AI agent can perform on a page, as JavaScript functions registered via a browser API.
For example, if your web app is a media player, you could register actions such as previous, next, play, pause, or search with WebMCP, to let AI agents use these actions via the browser. This way, not only would a real person continue to be able to use your media player, by interacting with the UI as normal, but an AI agent would also be able to detect the actions that are available, and invoke them, by calling into your webapp's code directly.
This would not only make it easier for the agent to know what to do, and how to do it, with fewer chances for mistakes than by using screenshots or the DOM, but it also puts you in the loop. You, as the web developer of the page, choose which actions you want to expose, what they're called, how they're described, what they do, and how they do it. It also lets you register different actions at different times, to reflect state changes on a web page for example.
Note that WebMCP doesn't prevent AI agents from using other means of analyzing or interacting with your page.
The MCP part in WebMCP stands for Model Context Protocol, which is a protocol that's now commonly used by AI agents to perform actions on behalf of users. There are many MCP servers nowadays, to do all sorts of things. The idea here, is to make the browser be an MCP server too, and expose actions that are available on the current web page, and registered via WebMCP. This way, the AI agent which the user is using can query the browser's MCP server for the actions that are available on the current page, and invoke them as needed, to fulfill the user's request.
Example
Let's take the example of a TODO list app, which lets users create, edit, complete, and delete tasks in a list.
Without WebMCP, an AI agent would have to understand the meaning of the webpage and which fields to use by looking at the DOM or a screenshot of the page.
With WebMCP, the AI agent is able to use the MCP protocol by connecting to the browser-provided MCP server, get a list of the available actions (or "tools", in MCP jargon) exposed by the web page, and then use any of these tools to complete the user request.
Here's what a add-todo WebMCP tool would look like:
window.agent.provideContext({
tools: [
{
// Metadata about the tool, for the AI agent.
name: "add-todo",
description: "Add a new todo item to the list",
inputSchema: {
type: "object",
properties: {
text: { type: "string", description: "The text of the todo item" }
},
required: ["text"]
},
// Implementation of the tool.
async execute({ text }) => {
// Code to add the todo item and update the UI.
// ...
return /* structured content response */
}
}
]
});Demo
Folks on the Edge team have started implementing a prototype, so we can get a feel for how it would really work in practice.
In the following video, you can see me using VSCode and Edge side by side. I've opened a personal project of mine in VSCode, and I'm using the Copilot Chat sidebar, in agent mode. In the video, I'm demonstrating how I might use this agent mode to do things on my project, like find colors, or image URLs, and so on, but also how I might communicate with the browser's MCP server to make it do things on the web.
That's where the Edge window, next to VSCode in the video, comes into play. In it, I've loaded my TODO list app. The agent in VSCode connects to the MCP server in Edge, which exposes the actions that the TODO list app registered. So, I can just ask my agent in VSCode to add the TODO items I need.
Feedback
As I mentioned before, this is an early proposal for now. There's nothing more important in the life of an early proposal than feedback from people who might need to use this when it exists.
So, if you're excited about this (in fact, even if you have an alergic reaction to it), or if you have different ideas for how to do something like this, then let me know on Mastodon, Bluesky, or LinkedIn.
Or, open an issue on the proposal's repository directly.
Any little bit of feedback can help.